La syndication : qu'est-ce ?
Important :
La syndication, c'est le fait de publier un contenu à différents endroits, sur différents supports et sous différentes formes, en particulier à un endroit différent de celui pour lequel ce contenu a été originellement conçu, généralement sous une forme abrégée, voire sommaire.
1. Origine : la syndication dans la presse et les médias

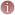
Dans le champ des médias, la syndication désigne le processus par lequel un contenu, offert sous forme de flux, est distribué sur différents supports qui n'ont pas participé à sa production.
Les supports achètent le droit de publication de ce contenu qui vient ensuite se mettre à jour automatiquement sans qu'un acte commercial individuel soit nécessaire, on parle d"abonnement" (subscription).
Exemple :
Site avec "abonnement "
Ce mécanisme est utilisé notamment dans la presse (éditoriaux, bandes dessinées...), pour les chaînes télévisuelles (séries TV...) et sur le web pour les sites commerciaux, de journaux en particulier.
Mais comme nous allons le voir le mécanisme de la syndication se généralise avec des caractéristiques particulières.
Exemple :
Le quotidien X est abonné au comic "Dilbert" auprès d'United Features Syndicate.
Dans son édition du 16 septembre, dans la page où sont publiés les comics est publié la bande du 16 (seconde ci-dessus), le lendemain, c'est celle du 17 qui est publié sans que celle-ci ait fait l'objet d'un acte d'achat particulier. Et ainsi de suite....
Quelques caractéristiques que l'on retrouvera pour la syndication de contenu web :
le contenu acheté a la forme d'un flux, c'est-à-dire la réitération, en principe périodique, d'un contenu renouvelé sous une forme homogène.
On parle d'"abonnement": lorsque je m'abonne à un périodique, journal ou magazine, je n'achète pas un exemplaire particulier mais un "flux" continu d'exemplaires pour une période déterminée.
le contenu est produit indépendamment du support sur lequel il sera publié. Lorsqu'un contenu a été contenu pour un support particulier, on parlera de syndication dans le cas où il sera vendu pour être publié sur un support différent de son support d'origine.
2. Qu'est-ce que la syndication de contenu web ?
La syndication de contenu web est une procédure qui permet de publier partiellement ou en totalité le contenu d'un site sur d'autres sites.
L'usage le plus important de cette procédure a pour but d'amener sur un site de référence de l'information glanée à différents endroits du web et de permettre ainsi à l'utilisateur de prendre connaissance des mises à jour en un lieu unique au lieu d'avoir à se rendre sur les différents sites d'origine.
Important :
Elle se fait par l'abonnement à un "flux de syndication" proposé par le site d'origine du contenu.
Explication en vidéo :
RSS in Plain English (CommonCraft, avril 2007)
RSS en bon français (adaptation par Vincent Durmont)
3. En pratique, comment cela se passe ?
a. Je repère un contenu intéressant dont je vérifie qu'il propose un flux de syndication
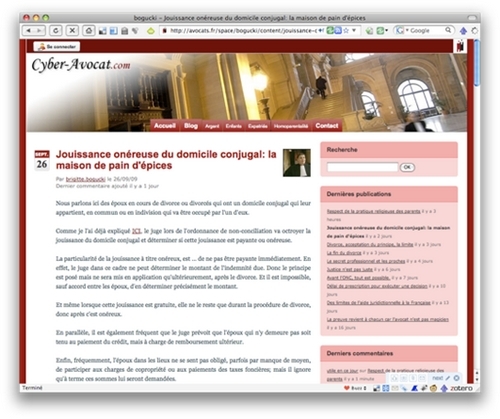
Une icône /logo signale la présence d'un flux de syndication dans la fenêtre d'adresse (URL) de la page web lorsque le flux de syndication a été repéré automatiquement par le navigateur.
Pour ce navigateur (Firefox 3), l'icône est le petit carré bleu figurant des ondes qui est à droite dans la fenêtre de l'adresse (Dans les versions antérieures de ce navigateur ainsi que dans la plupart des autres navigateurs, cette icône carrée est de couleur orange.).
Cependant le navigateur peut échouer à reconnaître des flux de syndication effectivement proposés par le site visité. Ils sont repérables par différentes icônes placées sur la page web ou simplement par les mots "RSS" ou "syndication" ou "feeds" ou encore "XML".
Dans le cas d'un blog, et plus généralement d'un site réalisé avec un outil de gestion de contenu web, un flux de syndication est à peu près toujours proposé.
b. Je m'abonne par l'intermédiaire de mon navigateur
Procédure
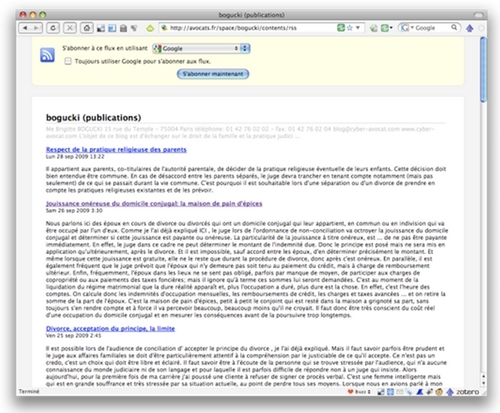
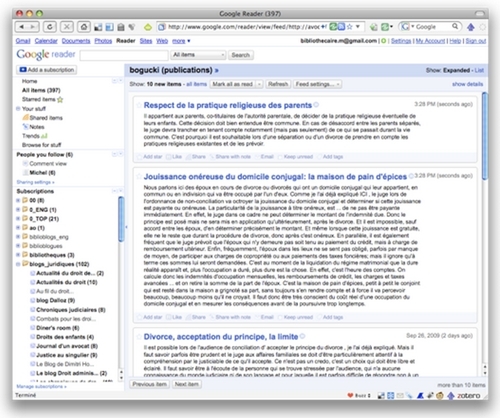
Les navigateurs modernes proposent une procédure automatique de syndication, paramétrable.
Il est cependant toujours possible, en particulier dans les cas où, pour une raison ou pour une autre la procédure automatique échoue, de réaliser l'abonnement "à la main" par un copier/coller de l'URL du flux de syndication dans une fenêtre dédiée du lecteur de flux (cf. infra).

Ici, nous suivons la procédure automatique, dans un navigateur Firefox 3 et avec le choix préalable de Google Reader comme lecteur-agrégateur.
J'ai cliqué sur l'icône bleue et se déroule une liste.
J'ai le choix entre deux utilisations possibles du flux de syndication :
soit en "live bookmark" dans le navigateur ou sur delicious. Il se comporte alors comme un dossier de favoris mis automatiquement à jour,
soit, et c'est ce qui nous intéresse ici, par abonnement.
Par ailleurs peuvent être proposés plusieurs formats de fichier de syndication.
Pour l'usage courant, la différence entre les différents formats est de peu de conséquence (Les différents formats sont plus ou moins riches en métadonnées descriptives. Et par ailleurs, le format atom n'est pas lu par certains lecteurs RSS utilisés pour la republication de flux.).
Enfin une même page peut proposer plusieurs syndications.
Typiquement deux sur un blog, comme ici : une syndication du contenu principal et une syndication des commentaires.
D'autres types de sites peuvent en proposer un nombre beaucoup plus grand, les sites de quotidiens par exemple.
Ici, nous sélectionnons le premier choix proposé qui correspond à l'abonnement au contenu principal du blog sous le format RSS 2.0.
Le navigateur m'ouvre alors une page qui me présente le contenu du flux de syndication à l'instant t où j'ai requis l'abonnement. Il est important de vérifier que le contenu présenté correspond bien au contenu souhaité avant de continuer la procédure. En effet, il n'est pas rare que l'on ait sur certains sites comme Wikipedia par exemple, une mauvaise surprise.
Il faut noter que ce qui est présenté ici n'est pas une page html normale mais l'interprétation de la page XML de syndication par un lecteur de flux de syndication intégré au navigateur.
Le menu déroulant me présente les principaux outils de lecture de flux de syndication. Je peux choisir une application non prédéfinie et la rajouter à la liste.
Je peux en cliquant sur la case carrée, demander au navigateur de sauter désormais cette étape et de toujours utiliser Google pour m'abonner. Cette simplification est dangereuse dans la mesure où je saute alors l'étape de vérification de la pertinence du flux proposé. Il ne m'est plus possible non plus de changer de choix d'outil de lecture. Je peux à tout moment revenir en arrière, restituer cette étape en passant par les préférences de mon navigateur.
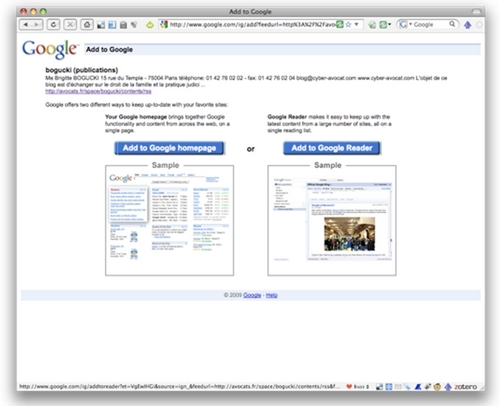
L'écran suivant me donne le choix entre les deux outils de lecture / agrégation que propose Google pour les flux de syndication (ce qui correspond aux deux types d'outils les plus courants) :
l'un, va publier les flux sur une page d'accueil personnalisée dans des widgets c'est à dire (window gadgets) de petits cadres ou fenêtres qui viennent se placer dans une page web pour y accomplir certaines tâches ou y publier certain contenu, ici un flux de syndication,
l'autre, va mettre les flux dans les dossiers et va permettre de lire l'ensemble des flux contenus dans un dossier, ou tous les flux ensemble comme un seul flux.
Si le premier outil permet une vue panoptique d'un ensemble restreint, le deuxième est plus puissant pour la consultation, la gestion et le traitement d'un grand nombre de flux.
Dans l'exemple que nous suivons, c'est la deuxième méthode, "Google Reader", que nous choisissons.
Le choix "Google Reader" cliqué, une nouvelle page s'ouvre où le flux est affiché dans Google Reader.
c. Je classe le flux dans mon agrégateur
Procédure
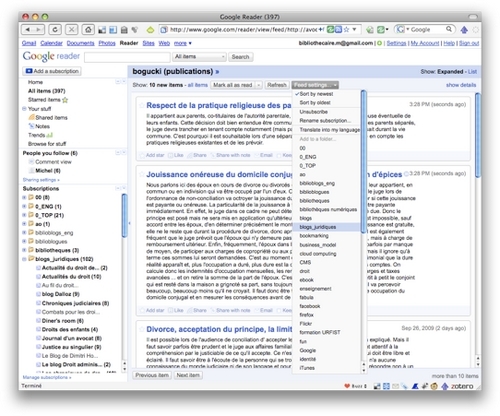
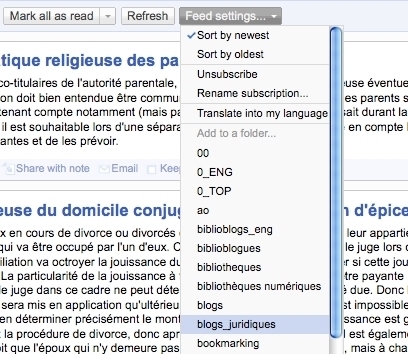
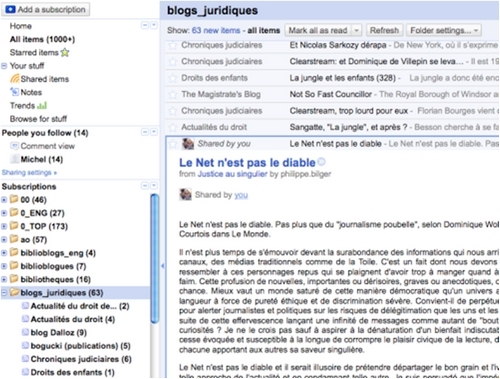
Une dernière étape me permet, par le menu déroulant "Feed settings" d'assigner le flux nouvellement abonné à un dossier, ici "blogs juridiques". Si aucun des dossiers créés jusqu'à présent ne me convient, je peux créer un nouveau dossier. Le choix se trouve tout en bas du menu déroulant.
Attention :
On tend naturellement à créer des dossiers regroupant les flux selon leur contenu.
Cependant, à partir du moment où le nombre de flux abonnés devient important, une autre logique de regroupement s'avère plus performante pour régler le "régime d'attention", c'est-à-dire : pour correspondre au degré d'attention (temps + disponibilité d'esprit) mobilisable.
Cela correspond au rangement des flux dans des dossiers organisés selon un principe de priorité.
Je vais créer un dossier regroupant les quelques flux qu'il faut absolument que j'ai lu dans une période donnée et correspondants à la périodicité de mon activité de veille (chaque jour ou chaque semaine...).
Google Reader permet de classer le flux dans plusieurs dossiers. Je vais donc classer mes flux selon une double logique : selon son continu et selon sa priorité.
Puisque Google Reader liste les dossiers alphabétiquement, je vais intituler numériquement mon ou mes dossiers prioritaires de façon à ce qu'ils se placent en tête de liste.
Je ne les multiplie pas : un ou deux, éventuellement répétés si j'ai plusieurs objectifs de veille bien distincts, voir sur l'exemple (C'est une méthode mise au point empiriquement. On peut faire mieux !).
Je suis désormais abonné à ce nouveau flux que je viendrai lire avec ceux précédemment abonnés au moment de faire ma veille.
d. Je lis le flux dans mon agrégateur
Procédure
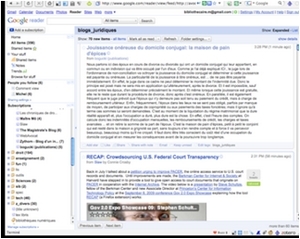
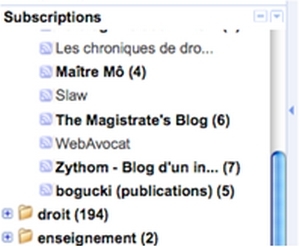
Je vais généralement consulter les flux auxquels je suis abonné au niveau du dossier dans lequel je l'ai rangé.
Par défaut, je ne ferai apparaître des flux que les éléments (items) nouveaux, ceux que je n'ai pas encore lus / consultés.
Les différents flux contenus dans un dossier sont fusionnés et apparaissent comme un seul flux.
Je peux toujours faire apparaître (comme dans l'exemple ici) les items déjà consultés et les flux sans éléments nouveaux.
Les dossiers vides sont en maigre et derrière l'intitulé de chaque dossier le nombre entre parenthèses indique le nombre d'items non lus restant dans le dossier.
Je peux également choisir de n'afficher qu'un flux individuel (alors réapparaît le menu "feed settings" qui me permet de modifier les paramètres du flux et en particulier de me désabonner.
e. Automatiquement mon agrégateur va marquer mon flux comme lu
Observation
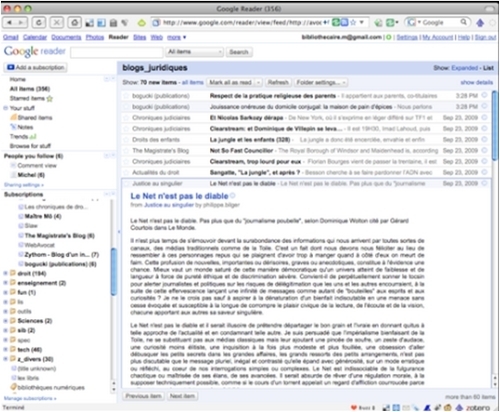
Lorsque je suis en mode extended comme ci-dessus, c'est-à-dire, lorsque l'ensemble du contenu du fichier de syndication est affiché item par item, chaque élément est automatiquement marqué comme lu lorsqu'il a été affiché.
Lorsque je dois parcourir un grand nombre d'items en peu de temps, soit que j'ai dû interrompre ma veille et que je la reprends, soit que je consulte des dossiers de moindre priorité, je peux passer en mode liste. Ne sont alors affichés que les titres des items avec leur provenance.
En ce cas, ils ne sont marqués comme lus que si je les ouvre pour en découvrir le contenu. De cette manière, je peux n'ouvrir que les items dont le titre m'aura suggéré que le contenu pourrait m'intéresser.
Les items lus sont en maigre dans la liste.
Il est possible de marquer comme lus l'ensemble des items d'un dossier par une action unique.
f. Je traite les informations pertinentes trouvées dans mes flux - et je peux partager ma veille
Procédure
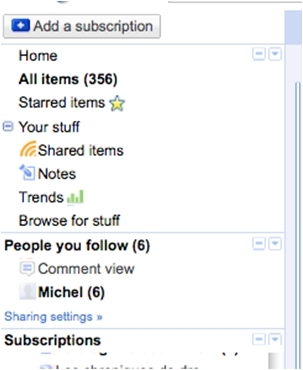
Au bas de l'affichage de chaque item dans Google Reader, une ligne de commande permet de traiter les items.
Je peux :
le mémoriser en le marquant comme favori,
signaler à mon réseau que j'ai aimé cet item,
le partager (voir plus bas),
l'annoter et partager cette annotation avec l'item lui-même,
envoyer un courriel pour communiquer cet item à quelqu'un d'autre,
garder cet item comme non pour qu'il me soit montré à nouveau lorsque je reviendrai sur GoogleReader,
enfin, modifier ses "étiquettes" (tags) : tous les items portent comme étiquette(s) le nom du ou des dossiers dans lesquels le flux dont ils font partie a été classé. Mais, il est possible de rajouter une ou des étiquettes aux items individuels. Ces tags rajoutés vont créer des dossiers où ce ne sont plus des flux qui sont regroupés mais des items, des éléments de flux.
Partage :
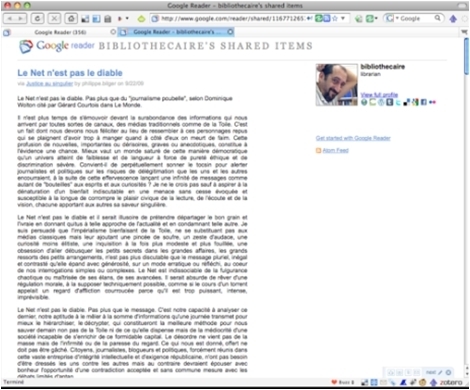
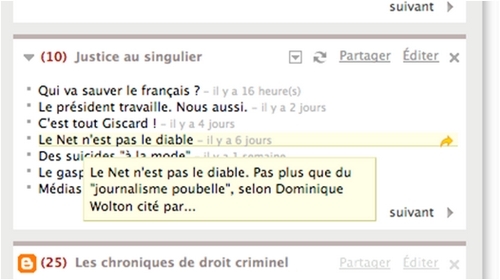
En cliquant sur "Share" je sélectionne les items que je veux mémoriser.
Mais à la différence de ceux que j'ai mémorisé en "favoris", je les "partage", c'est-à-dire que : je rends mon choix public soit pour les utilisateurs de Google Reader qui me suivent, soit en les publiant sur une page particulière. Une sorte de "pseudo-blog" où les billets sont affichés en ordre chronologique inverse.
Attention :
Le contenu publié est l'intégralité du contenu du billet tel qu'il se trouve dans le fil de syndication. C'est-à-dire que sa re-publication dépasse le cadre du droit de citation.
Conseils, trucs et astuces :
On peut considérer que l'auteur du contenu, en publiant ou en laissant publier un flux de syndication, donne un accord tacite à la republication mais ceci est contestable.
Il est donc recommandé de laisser à ce "pseudo blogue" son URL "ésotérique" et de ne pas la publier sur un site public.
Ce "pseudo blog" produit à son tour un flux de syndication au format Atom de sorte que les personnes qui vous auraient délégué une partie de leur veille peuvent elles-mêmes s'abonner aux résultats de votre veille dans leur lecteur de flux.
4. Qu'est ce qu'un "flux" de syndication web ?
Concrètement, un "flux" ou "fil" de syndication (anglais: feed (soit « nourriture »
ou « fourrage »
)), c'est une suite de fichiers XML dont chacun décrit le contenu, non la mise en forme de ce contenu, d'un même site ou d'une même partie d'un site à l'instant t. Typiquement le flux sera mis à jour, c'est-à-dire qu'un nouveau fichier pour l'instant t+1 sera généré, chaque fois que le contenu aura été modifié.
La syndication de contenu web n'est en réalité qu'une application particulière de la technologie XML appliquée au transfert de données sur le web.
a. XML
Attention :
"XML" vaut pour eXtensible Markup Language, "langage de balisage extensible".
Bien que le mot "language" apparaisse dans son intitulé et que conséquemment XML soit couramment défini comme un langage informatique, cette qualification peut induire en erreur.
Un langage, au sens courant du terme, requiert des règles de formation, une grammaire, et une sémantique, un vocabulaire. Dans cette mesure HTML peut être qualifié de langage puisqu'il me donne à la fois un vocabulaire et des règles de composition qui me permettent de créer des pages web directement "comprises" par mon navigateur.
XML ne se donne pas de sémantique a priori, c'est ce qui le rend extensible. Il ne définit que des règles de composition.
Pour qu'un fichier XML puisse être compris, il doit être composé suivant un "vocabulaire" particulier, un format ou "DTD (Document Type Definition ou « Définition de Type de Document »
) connu du "lecteur" ie de l'application qui va utiliser le fichier.
Atom ou les différentes versions de RSS sont de ces formats XML mais certains lecteurs ne les connaissent pas tous. Ainsi, il est préférable, à propos de XML, de parler de "métalangage" ou de syntaxe ou encore de méthode.
Les applications de la technologie XML sont nombreuses, principalement pour le transport de données et l'interopérabilité entre diverses applications mais aussi pour l'archivage.
Conseils, trucs et astuces :
Pour visualiser un fichier XML, il suffit de l'ouvrir avec le bloc note ou un autre outil de traitement de texte.
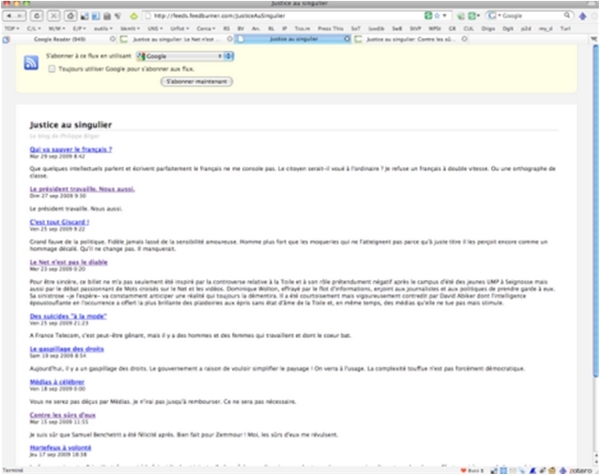
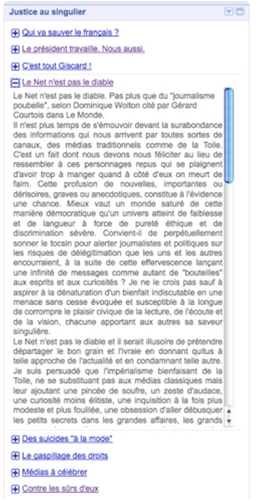
b. Billet sur le blog et dans Google Reader
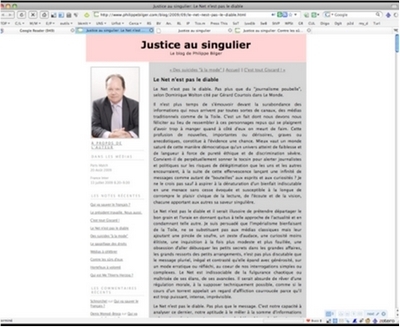
Dans GR :
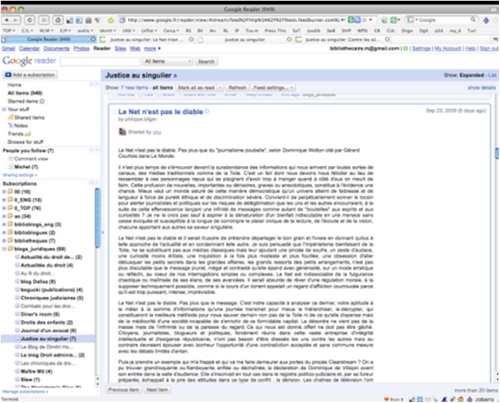
La version d'un billet de blog tel qu'affiché dans le lecteur / agrégateur Google Reader.
Le contenu du billet original peut-être affiché intégralement dans l'agrégateur ou seulement partiellement.
Pour le vérifier, je clique sur le titre du billet pour ouvrir le billet sur son site d'origine.
La "quantité de contenu" du billet affichée par le lecteur de flux est très variable. Elle dépend de deux types de facteurs :
En « amont », du côté de la production du contenu : | En « aval », du côté de la réception du contenu |
|---|---|
| Tous les lecteurs de flux ne vont pas extraire de la même manière du contenu des flux qu'ils traitent. Grand nombre de widgets (de même que le lecteur / extension de MediaWiki) ne publient que le titre de l'item et un lien vers le site d'origine. Les lecteurs-agrégateurs permettent un affichage succinct et un affichage le plus complet possible. |
Et bien sûr l'environnement du contenu, mise en forme et contenus marginaux, ne se trouvent que sur le site d'origine.
c. Code HTML du billet
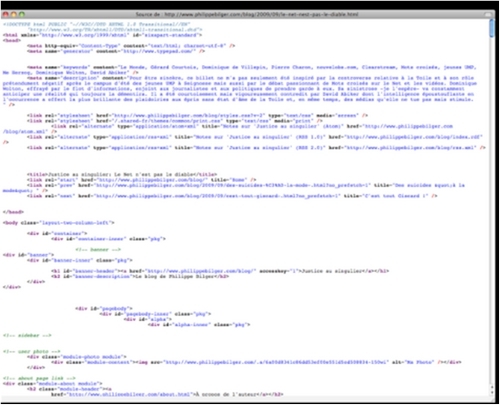

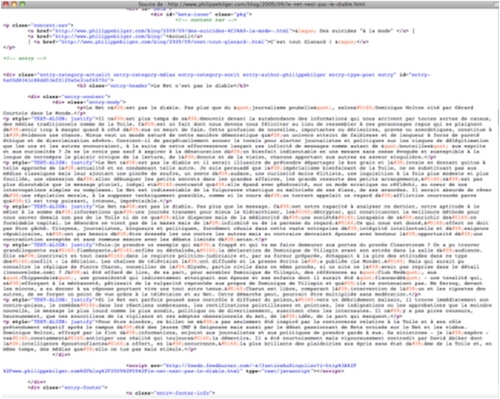
On affiche le code source des pages affichées dans le navigateur Firefox par la commande : Affichage > code source de la page (ou cmd / ctrl U).
Le code source s'affiche alors dans une nouvelle fenêtre.
Les balises HTML donnent des informations techniques et des informations de contenu sur la page, puis mettent en forme le contenu qui sera publié.
En réalité, le format utilisé ici n'est pas du HTML simple mais du XHTML (Extensible HyperText Markup Language), c'est-à-dire une version de HTML conforme à la "grammaire" XML.
Le contenu principal du billet occupe une partie relativement restreinte de la page de code (observer l'ascenseur sur la barre de défilement à droite).
d. Le fichier de syndication
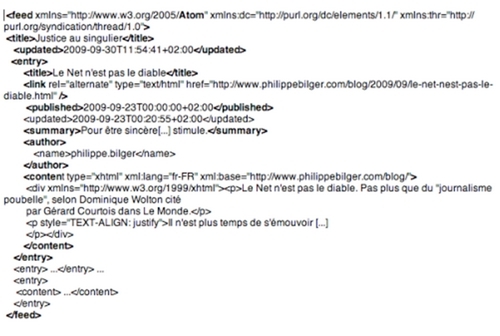
RSS 2.0 :
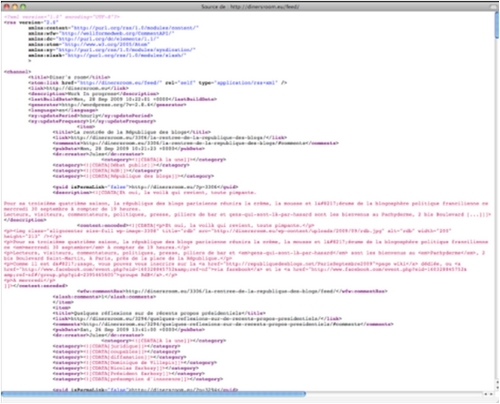
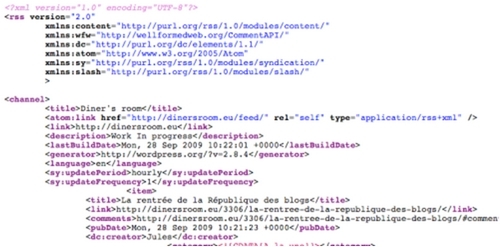
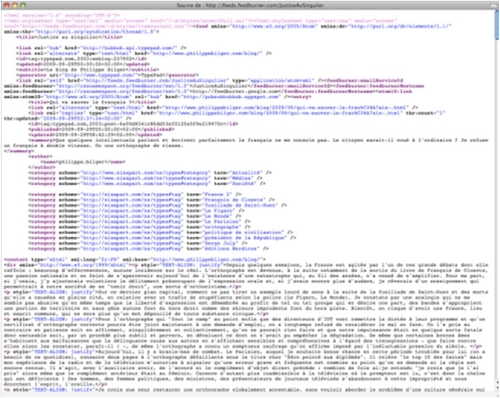
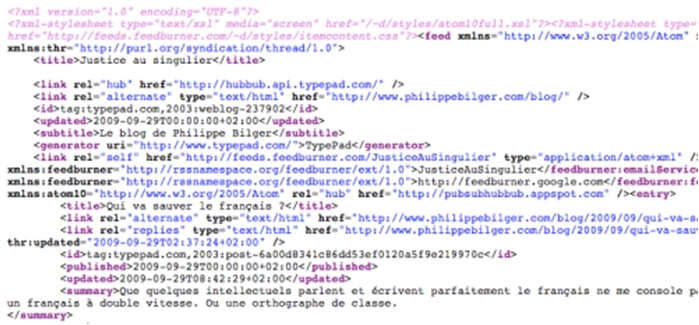
Si je clique sur l'icône bleue (comme au cours de la procédure supra), mon navigateur affiche le fichier de syndication.
J'affiche le code source du fichier de syndication qui reflète le contenu du blog tel que mis à jour au moment où je l'affiche.
Attention :
Bien distinguer le flux ou fil, feed, du fichier XML lui-même : c'est la suite dans le temps des fichiers de syndication, publiés à la même adresse, qui constitue le flux.
On constate certaines similitudes et certaines différences avec le fichier HTML (Le fichier HTML correspondant au fichier de syndication n'est en réalité pas le fichier encodant la page du billet mais celui encodant la page d'accueil de tout le blog.) :
Similitudes | Différences |
|---|---|
Organisation générale du fichier. Utilisation de balises :
| Contenu différent des balises :
Compacité beaucoup plus grande du fichier. Plus grande "lisibilité" du fichier. |
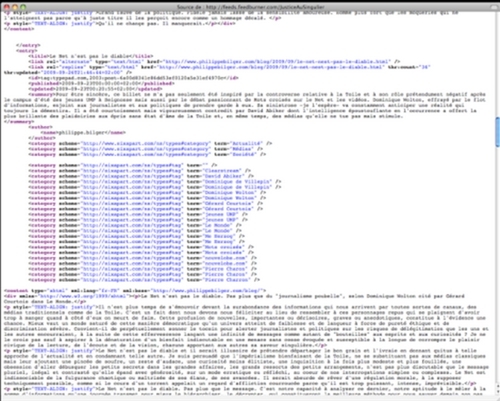
A la différence du code HTML (ou XHTML) où le contenu des balises est pré-défini, XML ne définit pas le contenu de ses balises.
Exemple :
Je pourrais écrire <titre> ou <toto> à la place de <title>, à condition que la balise <toto> soit fermée par une balise </toto>.
C'est le format Atom, défini en tête de fichier qui va définir le contenu des balises (le vocabulaire).
L'extrait ci-dessus souligne les éléments principaux de ce balisage. On remarque en particulier que le fichier est daté (balise "<updated>"), ce qui lui permet de prendre sa place dans un flux.
On donne ci-dessus deux copies d'écran affichant un fichier de syndication en format RSS 2.0.
Une comparaison avec le fichier Atom montre que si le contenu et l'organisation des fichiers sont analogues, le "vocabulaire", le contenu des balises est différent.
Pour la plupart, elles sont susceptibles d'une "traduction" d'un format dans l'autre.
e. Multi-publication du flux
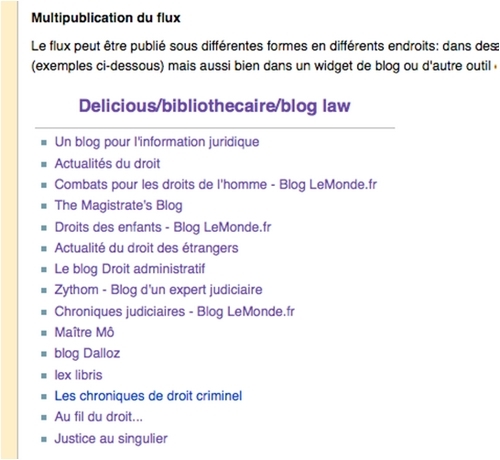
Le flux peut être publié sous différentes formes en différents endroits :
dans des widgets sur une page d'accueil personnalisée comme iGoogle ou Netvibes,
dans un lecteur-agrégateur sophistiqué comme Google Reader,
dans un widget de blog ou d'autre outil de gestion de contenu web,
dans un article de wiki, etc...
5. La syndication de contenu : une pratique du web 2.0
a. Les formats
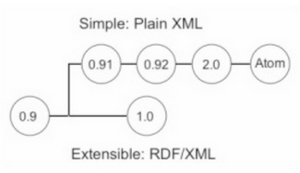
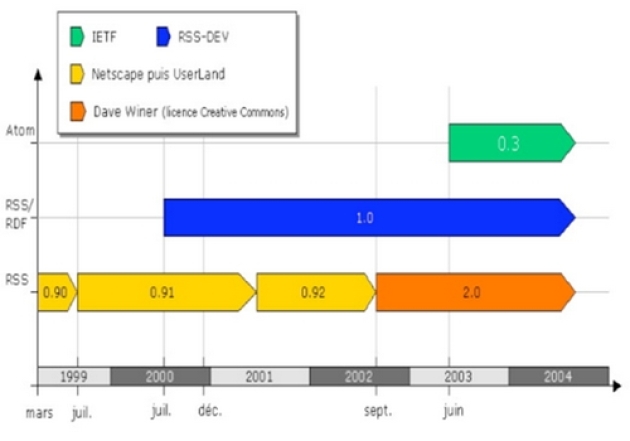
Source: Pablo Iriarte CHUV Lausanne
Attention :
Les formats de syndication se distinguent essentiellement quant à la richesse des métadonnées incluses et corrélativement quant aux ambitions sous-jacentes.
Ces différences apparaissent dans les développements de l'acronyme RSS selon les diverses versions.
RDF Site Summary pour RSS 0.90 and 1.0,
Rich Site Summary pour RSS 0.91 à 0.94,
Really Simple Syndication pour RSS 2.0.
Cette diversité recouvre deux lignes de formats: 0.90 et 1.0 veulent intégrer le modèle de graphe RDF (Resource Description Framework), langage de base du web sémantique, soit un format ambitieux, 0.91 à 0.94 et 2.0 à quoi rattacher (avec un vocabulaire de base différent mais une structure analogue) Atom sont plus simple et orienté non vers de possibles applications sémantiques mais vers l'usage qui se développe exponentiellement entre 2000 et 2003 à savoir la syndication. Ainsi, malgré les apparences, le format 2.0, le plus récent, est plus proche de 0.91 que de 1.0. Son développement de l'acronyme, Really Simple Syndication, atteste de cette ambition pragmatique, adapté à un usage massif.
Pour les besoins pratiques de la veille, ces précisions sont de peu d'importance: les différents formats se comportent de façon analogue voire identique pour les lecteurs agrégateurs de flux. Le seul problème de format qui peut se poser est l'incompatibilité d'Atom pour certains lecteurs.
b. Adoption
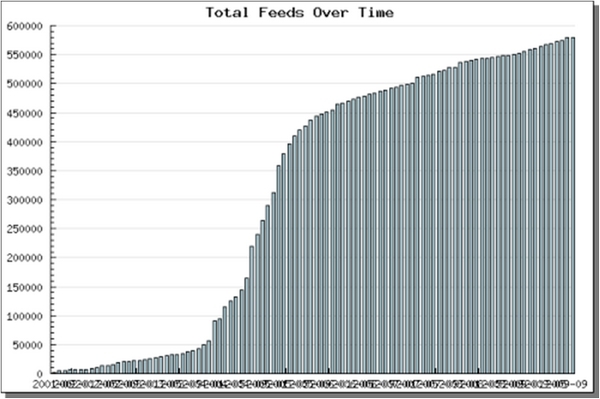
Le premier graphique montre l'évolution du nombre de flux de syndication produits entre 2001 et septembre 2009. Il montre une progression extrêmement rapide, exponentielle entre 2001 et 2005. Au cours de l'année 2005 la progression se ralentit fortement sans s'arrêter néanmoins. La première période correspond à la vulgarisation de la technologie et aussi à l'arrivée des outils de gestion de contenu web ("blogosphère", 2002 - 2003) qui, en raison de leur technologie, vont tous produire des flux de syndication générés automatiquement.
La seconde courbe qui montre l'évolution du nombre d'utilisateurs de flux de syndication présente un profil très différent. Si l'on a bien une progression exponentielle, moins spectaculaire, dans les mêmes années et pendant un peu plus d'une année ensuite que celles de la progression exponentielle de la production de flux, malgré un ralentissement modéré fin 2006.
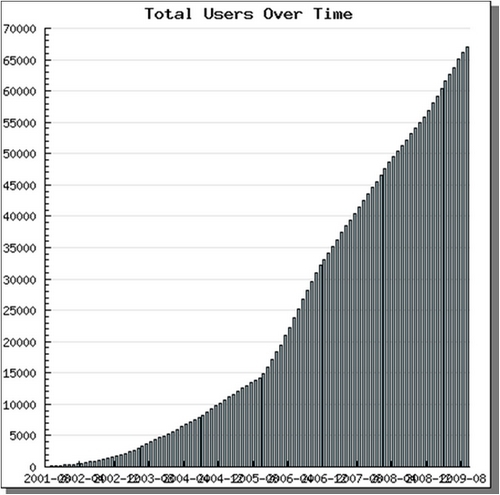
Si l'on a bien une progression exponentielle dans les premières années (2001-2006), elle est moins spectaculaire que celle de la production et ensuite, malgré un ralentissement modéré, elle continue de façon linéaire sur un rythme important.
Remarque :
Ces deux graphiques montrent que si la syndication est entrée dans une phase de maturité quant à l'offre (mais ce serait à nuancer, voir infra), elle est loin d'avoir fait le plein du côté de l'usage. La vigueur maintenue de sa courbe d'adoption atteste que cet important retard de la demande sur l'offre tient moins à une inadaptation de la technique aux besoins ou aux usages de ses utilisateurs potentiels qu'à sa nature peu intuitive et à la nécessité d'une initiation pour l'utilisateur moyen.
Au vu des chiffres, il peut sembler que la syndication n'ait plus quant à la production, à la différence de l'usage, de nouveaux territoires à conquérir. L'approche quantitative est ici trompeuse, une approche qualitative montrerait qu'en réalité les flux de syndication manquent encore massivement sur des catégories sites où ils seraient utiles, où ils sembleraient à première vue indispensable: catalogues de bibliothèques, bases de données (voir infra l'état de l'offre), sites officiels (le Journal Officiel par exemple), etc. Dans ce domaine comme dans d'autres sur le web, les sites non officiels, non professionnels, à usage individuel et / ou privé plutôt que professionnel, sont souvent en avance et plus efficace, et c'est plus vrai encore en France que d'en d'autres pays d'importance comparable.
c. Syndication et gestion de contenu web
Attention :
La popularisation de la syndication est liée au développement des outils de gestion de contenu web (CMS : Content Management System).
On désigne par ce nom un ensemble d'applications web bâties autour des mêmes principes technologiques et qui facilitent la publication sur le web. Ce sont, en particulier :
les blogs, où le contenu est organisé en billets publiés sur la page d'accueil du site en ordre anté-chronologique c'est à dire le plus récent sur le dessus où chaque billet a sa page propre ;
les wikis, à finalité d'écriture collaborative, où le contenu est organisé en pages ou articles eux mêmes organisés en réseau par des liens internes.
Ces liens sont caractérisés par la facilité d'écriture et la perméabilité entre la fonction de lecture et la fonction d'écriture. La plus célèbre est bien sûr Wikipedia mais dont les applications possibles sont nombreuses et encore sous-exploitées.
les autres 'outils de gestion de site' ou CMS au sens restreint, qui visent à intégrer toutes les fonctions d'un site web classique de type portail en particulier.
Ces outils, on parle de moteurs, (« Moteurs » plutôt que logiciels parce qu'ils ne fonctionnent pas à partir de fichiers exécutables dédiés mais par une combinaison de logiciels généralistes et de fichiers comme on va le voir.) peuvent être hébergés "dans les nuages", c'est-à-dire sur les serveurs de l'application, ou bien ils peuvent être installés par l'utilisateur sur un serveur sur lequel il a la main.
Le premier cas est le plus confortable pour l'utilisateur qui ne se préoccupe de l'application que pour la paramétrer selon des choix préparés par l'application mais sa liberté est limitée.
Le second cas symétriquement permet un plein contrôle de l'application mais demande à l'utilisateur de posséder ou de pouvoir disposer de compétences informatiques.
En particulier il existe des méthodes de publication intermédiaire entre la gestion de contenu web et le html statique. Mais leur introduction compliquerait le propos sans le modifier sur le fond.) montre comment gestion de contenu et syndication web sont liés.
Dans la partie haute du schéma est rappelée la chaîne de production du contenu en HTML statique, si l'on veut, la manière "web 0.1" :
Je réalise une page web sous forme de fichier HTML à l'aide d'un éditeur de texte ou plus souvent d'un logiciel d'édition web comme DreamWeaver ou FrontPage.
Lorsque je suis satisfait de ma page, je la charge, via FTP (File Transfer Protocol) sur le serveur web de mon site pour lequel j'ai les autorisations nécessaires.
Lorsqu'un internaute va vouloir lire ma page, mon navigateur, via HTTP (HyperText Transfer Protocol), va aller copier le fichier depuis le serveur web sur son disque dur puis l'interpréter et l'afficher de façon lisible pour l'internaute.
Cette méthode, où le contenu et sa mise en forme sont codés en même temps dans le même fichier, exige des compétences éditoriales et des compétences techniques.
Elle correspond à la grande époque des webmasters c'est à dire des personnes qui au sein d'une organisation possédaient ces compétences.
Attention :
La première fonction des outils de gestion de contenu web va être de séparer les compétences techniques des compétences éditoriales et élargir ainsi considérablement la base humaine de production de contenu web.
Les outils de gestion de contenu fonctionnent pour leur presque totalité à l'aide d'un gestionnaire de base de données (MySql par exemple) et d'un langage de script (PHP par exemple).
Exemple :
Lorsque je veux publier du contenu sur le web, sur un blog par exemple, je vais me connecter sur l'interface web d'administration du blog en m'identifiant.
Je vais ensuite entrer du contenu dans un formulaire comportant plusieurs cadres :
un pour le titre du billet,
un pour le texte du billet,
un autre pour les tags ou étiquettes (mots-clés décrivant le contenu de mon billet),
etc...
Remarque :
Lorsque je sauvegarde mon billet pour publication, ces différents éléments vont être envoyés dans une base de données, dans des champs correspondant aux fenêtres de saisie du formulaire.
D'autres champs sont alimentés automatiquement :
un champ "auteur" puisque je me suis identifié avant de saisir le contenu de mon billet,
un champ "date" correspondant au moment où je sauvegarde mon billet.
Ensuite un fichier de script va extraire de la base et mettre en ordre les données correspondant au contenu du billet. Ces données vont être mises en forme selon une feuille de style CSS valable pour tous les billets du blog. Le fichier HTML correspondant à la page d'accueil va être mis à jour et une nouvelle page est créée pour le billet.
Ainsi le code HTML, qui sera lu par l'internaute, n'est produit qu'à la fin du processus.
Pour publier je n'ai plus besoin de compétence HTML ni de droits d'accès au serveur. Je dois seulement m'identifier comme personne habilitée à écrire sur le site.
Mais cette nouvelle méthode a une autre conséquence : en faisant passer le contenu par une base de données et en le répartissant à cette fin dans des champs, je donne des informations sur la nature des contenus que je publie. L'application va pouvoir, à l'aide d'un fichier de script particulier, extraire le contenu de mon site et le publier sans renseigner sa mise en forme particulière sur son site d'origine. Seule la nature des différents segments qui le compose sont spécifiés.
Ce fichier, automatiquement produit par l'application chaque fois qu'un nouveau contenu est ajouté, est le fichier de syndication.
Il pourra être lu sur d'autres sites que son site d'origine dans différents formats correspondants à ces nouveaux sites (En particulier va être possible une mise en forme particulière adaptée aux contraintes spécifiques des téléphones mobiles.).
Syndication et gestion de contenu web sont ainsi intimement liées. Ces deux technologies sont à la base de la mutation des pratiques de l'internet qu'on a appelé à la suite de Tim O'Reilly le "web 2.0".
